In case you’re pretty content with your data lake (or not at all), it’s time to upgrade the implementation around the data lake.
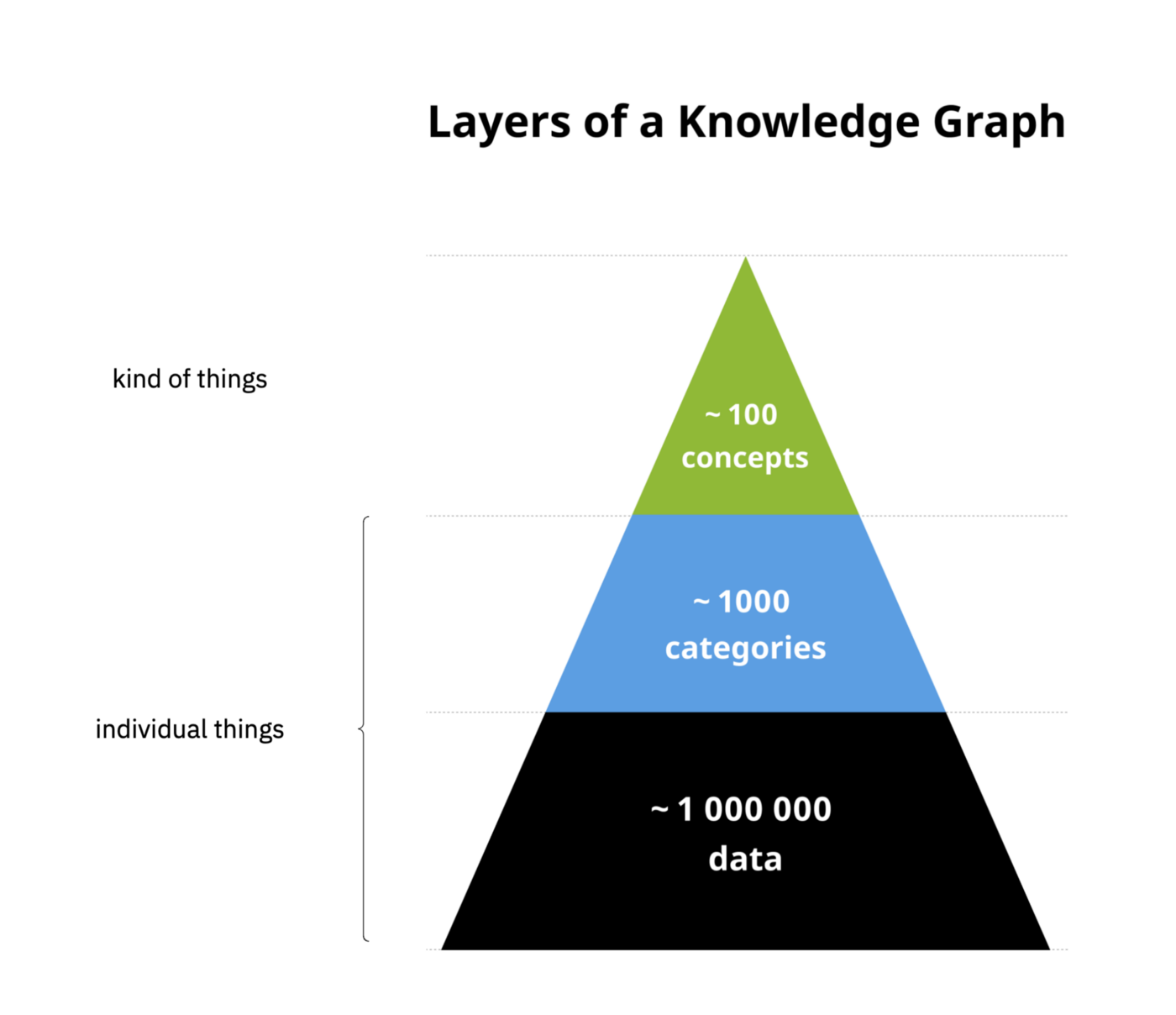
While logically a data lake can still consist of raw, enriched and curated (or bronze, silver and gold, just pick a label) and you can still apply all the data mesh principles, the technology has already taken the next step in that you don’t have to physically create these layers, that you don’t have to set everything up in advance with DWH, SQL and Spark instances.
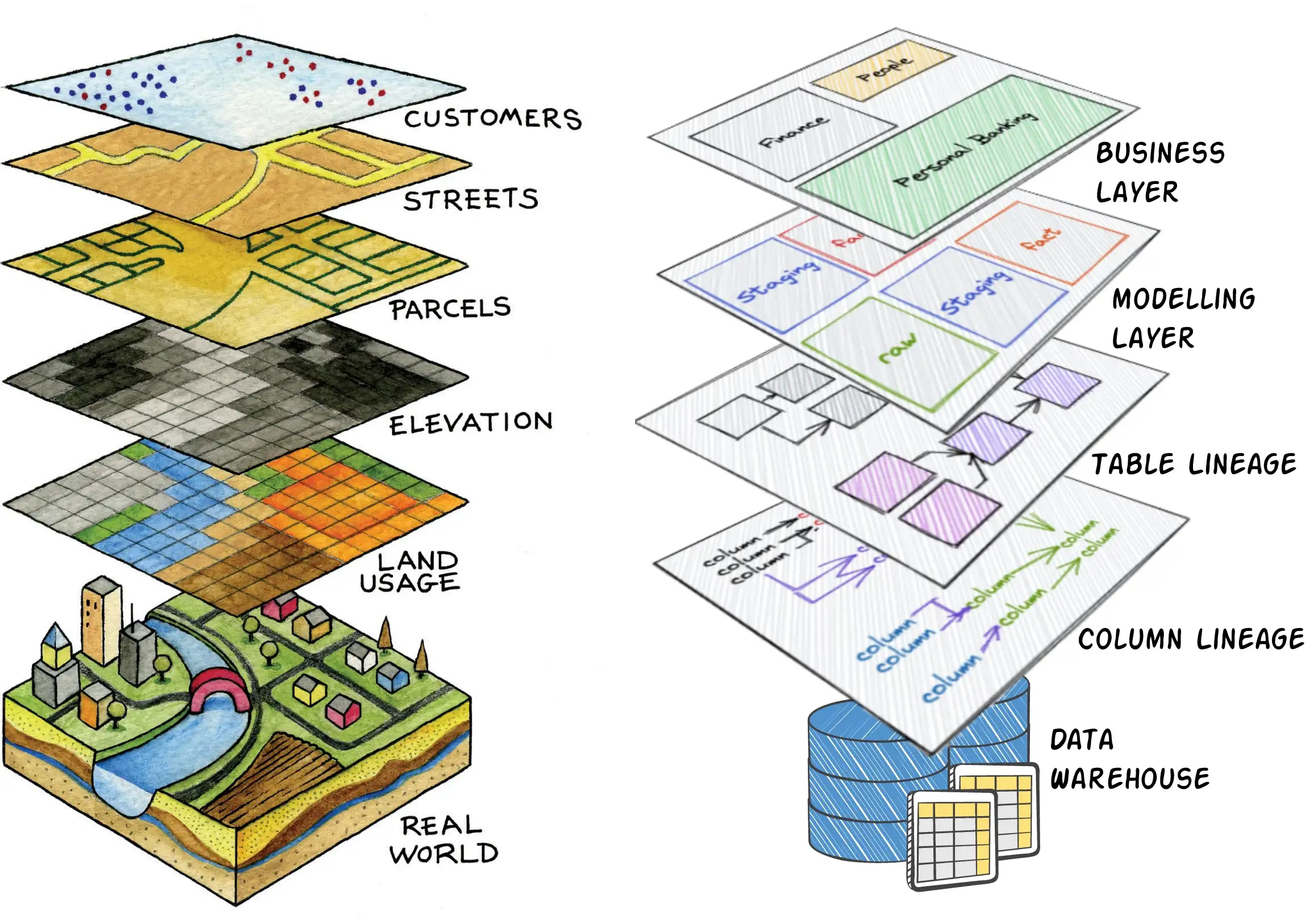
The Data Lakehouse has a bottom side (for ingestion of data) and a top side (for addressing all kinds of awesome functionality). What happens in between, you have logical control over that, but physically the Data Lakehouse takes care of it.
[Just a quick note, to pique the interest of those who may not have gotten to this yet].
For completeness, Data Lakehouse is a term frequently used by Databricks. However, it is quite possible to use cloud components to create your own data lakehouse or look at what other vendors have similar products.