Voor het geval je aardig content bent met je data lake (of juist helemaal niet), het is tijd om de implementatie rond het data lake te upgraden.
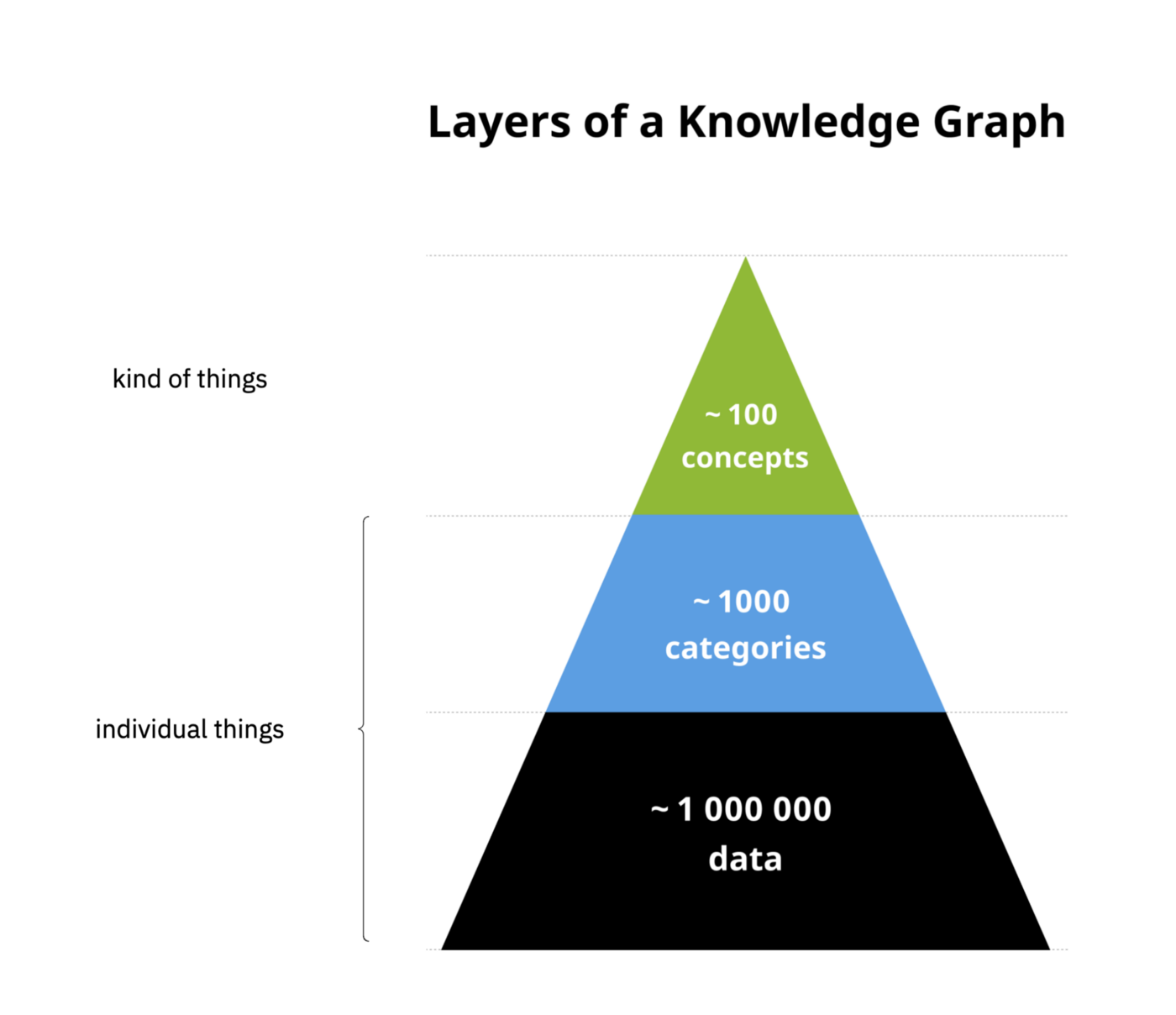
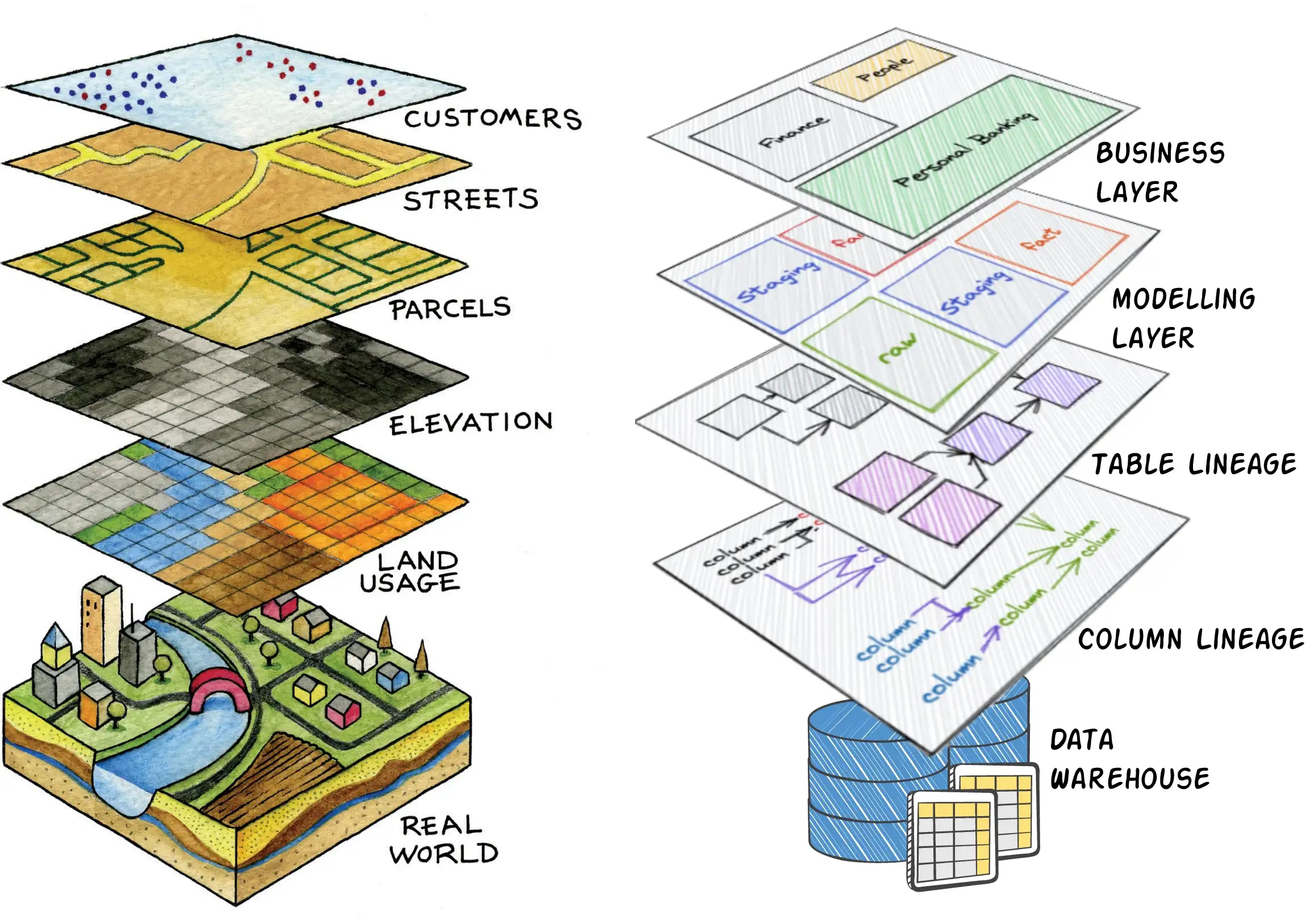
Hoewel logisch een data lake nog steeds uit raw, enriched en curated kan bestaan (of brons, zilver en goud, kies maar een label) en je nog steeds alle data mesh principes kunt toepassen, heeft de technologie alweer de volgende stap gemaakt in dat je deze lagen niet fysiek hoeft te maken, dat je niet van te voren alles hoeft in te regelen met DWH, SQL en Spark instances.
Het Data Lakehouse heeft een onderkant (voor ingestion van data) en een bovenkant (voor aanspreken van allerlei te gekke functionaliteiten). Wat er tussenin gebeurt, daar heb je logisch invloed op, maar fysiek regelt het Data Lakehouse het.
[Even lekker kort door de bocht, om interesse te wekken bij diegene die hier mogelijk nog niet aan zijn toegekomen.]
Voor de volledigheid: Data Lakehouse is een term die door Databricks veelvuldig wordt gebruikt. Het is echter heel goed mogelijk om met cloud componenten je eigen data lakehouse te maken of te kijken wat andere leveranciers aan vergelijkbare producten hebben.