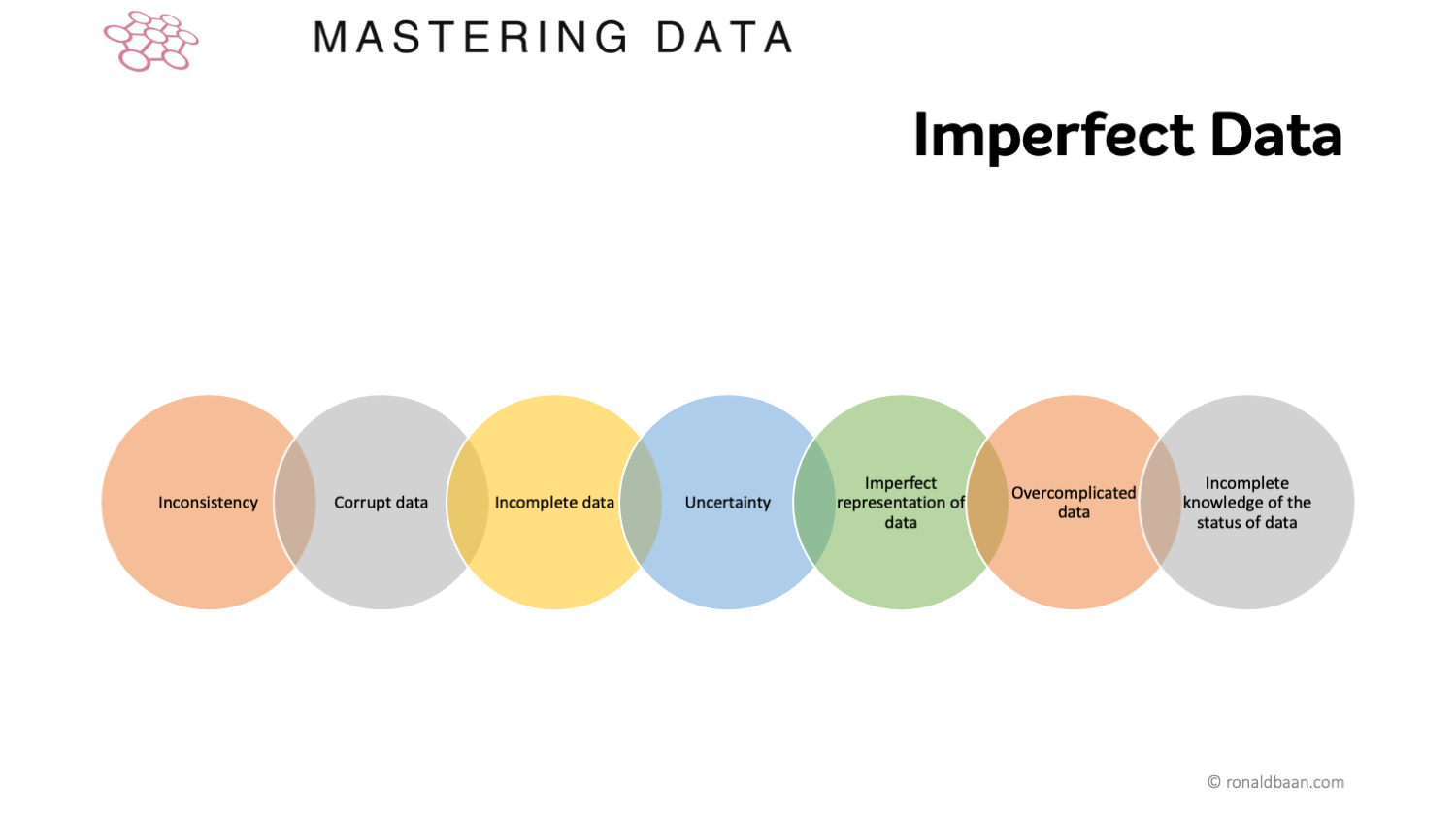
Does data have to be 100% perfect before you can do anything? Is data ever perfect?
How we deal with imperfection completely determines what value we can create with data and whether the time and effort we spend on data are useful investments or stopgap measures that just cost money and time.
Mindset: what can be done instead of what cannot be done
It’s so easy to say you can’t go forward if something isn’t better. However, there is no end to what we can wish for to get even better. Developments always start with imperfect situations where you can still achieve something better with imperfect means, imperfect insights. The first light bulb is nothing like the cool LED lights we have now and yet we got there.
With every step you take, it gets better. It’s not a question of yes or no, it’s about more and better.
Accuracy
A consequence of imperfections can be that some things cannot be done, even with fixes. This is unfortunate, but sometimes the reality.
The consequence may also be that imperfections reduce accuracy. That is much less of a problem than when something cannot be done.
You often indicate accuracy with a lower limit and an upper limit, possibly with an average or median. This still gives you a picture.
When I used to want to know from my project manager how expensive a project was going to be, he never knew. Then I would say more than 1 Euro and less than 10 million? Yes, probably more than 10,000 and less than 25,000 Euro. After some further questioning, talking and analysis, we then always came to a better accuracy, where the difference between the lower and upper limit had been given a reasonable value. So a bandwidth can already be useful.
Corrections and feedback
Some imperfections are easy or less easy to fix by writing some code, etc. This is good for speed, but less good for durability. Assume that imperfect data, even without your feedback, gets more and more perfect, so your fixes are no longer needed and may even cause problems.
Fixes are always extra costs in creating and maintaining and go against the principle we should all have: tackle problems at the source. Especially for data, this is crucial.
Of course, in practice this is often difficult. The owner of source data is certainly not waiting for extra work, because often, for the purpose for which it is used at source, it is sufficiently good. Then budget, people and a schedule come into play, so very quickly this will usually not be resolved, but this is the most sustainable way.
Often data is also used from an external party, e.g. CBS, Kadaster, KNMI or a commercial party. ALWAYS contact these parties if there are imperfections in their data. Assume that you are not the only one affected, so it is also an important signal for them and they will definitely want to deliver better data and they can only do so if they know what is imperfect.
Don’ts
Possibly some fewer don’ts, but along with recommendations. Be careful about some things:
- Don’t miss the imperfections in your analysis. Know they are there, which ones they are and take them into account, fix them in your dataset. That way, you may still be able to do a lot;
- Don’t over-analyse the data if you have imperfections. It is precisely with imperfections that you can sometimes see strange (aka ‘interesting’) things and check whether that is caused by imperfections in your data. If so, you may have reached an analysis limit;
- Don’t get stuck in the data, but find what’s behind the data and see if you can still arrive at actions and recommendations based on the data.
Be a realistic optimist and see what can be done!